Пусть имеются 10 моделей автомобилей, условно обозначенных буквами A…J. Респондентов спрашивают о восприятии их подобия. Опрашиваемому предлагается 45 карточек с парами автомобилей. При этом в инструктаже перед опросом говорится, что конкретные атрибуты, характеристики не важны, важно лишь общее восприятие схожести или различия. Респонденты должны расположить карточки в ряд от самой схожей пары до самой несхожей. Для простоты вначале можно отсортировать карточки по категориям, например: похожие, не очень похожие, очень не похожие, а затем располагать в ряд карточки внутри каждой категории.
Это наиболее простой вариант опроса. Карточки располагаются как показано на Рис. 37, a. Респондент в данном случае считает, что наиболее похожи друг на друга элементы исследования A и С. Чуть менее похожи элементы D и E, еще менее – элементы F и G и т. д.
Возможно использование несколько более сложного метода, при котором допускается одинаковая похожесть и «большие» различия в степени похожести (Рис. 37, б). Здесь респондент, расположивший карточки от самой близкой пары до самой несхожей, считает, что F отличается от J так же (в той же степени), как B отличается от D, причем эта похожесть меньше, чем похожесть D и E. Он считает также, что различия между A и B «значительно больше», чем различия между B и E.

Рис. 37 . Расположение карточек при опросе
Однако при проведении опроса по второму варианту больше времени тратится на инструктаж респондентов. Лучше, если респонденты отвечают в присутствии интервьюера, который может разъяснить им неясные моменты и напомнить о правилах раскладывания карточек. Действия по варианту б) могут возникнуть, когда сам респондент скажет, что на его взгляд расстояние в одной паре такое же, как и расстояние в другой.
Анализ проводится по каждому респонденту отдельно. При расположении всех карточек в ряд различия («расстояния») между моделями автомобилей ранжируется числами от 1 до 45. Расстояние между A и С принимается равным 1, что означает наибольшее сходство. Значение 2 приписывается расстоянию между D и E и т. д. Расстояние, равное 45 приписывается наименее похожей паре.
При более сложном варианте ответов (Рис. 37, б) расстояние между A и C принимается за 1, между D и E – за 2, между F и J, а также между B и D – за 3, между B и E – за 4, между A и B – за 6, между A и J – за 7 и т. д.
В результате получается матрица «расстояний» размерностью 10х10. (Она аналогична таблице расстояний между городами в атласе автодорог).
Далее полученная матрица вводится в компьютер и запускается процедура многомерного шкалирования.
Компьютеризированная процедура многомерного шкалирования позволяет ответить на вопрос о количестве атрибутов, использованных при ранжировании сходства, а также о взаимном расположении объектов в пространстве этих атрибутов.
Программа, действие которой основано на результатах работ Шепарда [38], пытается распределить точки, соответствующие объектам, в пространствах различной размерности.
Рассмотрим простейший пример с тремя объектами. Пусть это будут три автомобиля. Пусть, далее, автомобиль A самый дорогой, В имеет среднюю цену, C – самый дешевый. Если респондент оценивает их только по одному параметру (цене), то он укажет расстояния AB=1, BC=1, AC=2. Действительно, расстояние между A и C максимально. Точки, соответствующие трем автомобилям, располагаются без искажений на прямой (Рис. 38, а).
Если же респондент указал все расстояния равными 1, то это означает, что он имел в виду уже не один параметр. Если, например, автомобили A и B схожи ценой, то автомобили A и C схожи чем-то другим. В одну линию такие точки можно расположить только с искажениями. Программа попытается разместить эти точки с минимальными искажениями расстояний и укажет стресс (общую меру искажения расстояний). В данном случае точки можно без искажений разместить в плоскости (Рис. 38, б).

Рис. 38 . Расположение объектов при многомерном шкалировании
Теперь можно добавить еще один объект (D). Если респондент рассматривал автомобили по двум параметрам, то объект D будет расположен, например, как показано на Рис. 38, в. В этом случае расстояние от A до D будет бόльшим (например, 2). Если же респондент указал все расстояния равными, то для четырех объектов:
q ошибка размещения на прямой (размерность 1) будет велика;
q ошибка размещения в плоскости (размерность 2) будет меньше, но все же значительна;
q ошибка размещения в объеме (размерность 3) будет очень мала (Рис. 38, г).
Видно, что при росте размерности появляется больше возможностей для размещения точек. Поэтому для заданного набора расстояний стресс будет уменьшаться с ростом размерности.
Идея метода заключается в поиске минимальной размерности, сохраняющей полученные расстояния или дающей малые искажения. Если график зависимости стресса от размерности резко падает до небольшого значения при определенной размерности, то это свидетельствует о наличии определенного количества измерений, которыми руководствовались респонденты. На Рис. 39 этот спад происходит при размерности, равной трем, поэтому для данного случая количество важных измерений равно трем.
Наличие небольшого убывающего стресса при больших размерностях обусловлено случайными отклонениями, в первую очередь – достаточно грубым назначением расстояний в виде последовательности целых чисел
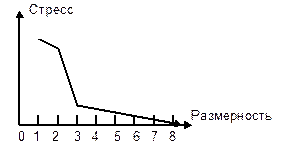
Рис. 39 . Зависимость стресса от размерности
Считается, что стресс, равный 11…20% – плохо, 6…10% – хорошо, 1…5% – отлично, <1% – идеально.
Программа также выводит картинку расположения точек, соответствующих элементам исследования, в виде двумерной или трехмерной диаграммы. Расположение осей аналогично расположению факторов методе главных компонент: ось X располагается так, что разность проекций на эту ось точек, соответствующих элементам, исследования, была наибольшей. В результате ось X можно считать самой важной, ось Y – второй по важности, а ось Z – наименее важной.
Для определения имен осей (атрибутов) можно пользоваться следующими методами:
1. Респондентов просят описать элементы исследования (для примера – модели автомобилей) с помощью различных атрибутов. Обычно предлагаются интегральные атрибуты, такие, как комфортность, современный стиль, престижность. Исследователь ищет корреляцию между проекциями точек на некоторую ось и полученными при опросе оценками атрибутов.
2. Оси сопоставляются с известными характеристиками, такими как цена, размер, престижность. Если степень совпадения высока, например, по оси X модели автомобилей расположены от дорогой до дешевой, то ось именуется как цена.
3. Имена координатных осей придумываются на основе предшествующего опыта.
Пусть координаты получили название «комфортность» и «экономичность». Если для некоторого автомобиля из карты следует комфортность, но неэкономичность и многие респонденты высказывают аналогичные мнения, то следует обратить внимание на совершенствование двигателя.
Полезно ввести в карту идеал. Он вводится из следующих соображений. Все автомобили (теперь уже не пары) ранжируются по предпочтению. Предполагается, что идеал должен быть ближе всего к самому хорошему автомобилю и дальше всего – от самого плохого. Координаты идеала также рассчитывает компьютер.
Чтобы успешно применять вышеописанный метод, следует иметь четкий ответ на следующие вопросы.
q Какой продукт, марка исследуется?
q Какие элементы исследования участвуют в сравнении? Например, какие безалкогольные напитки: с сахаром, без сахара, витаминизированные, газированные? Или речь идет о торговых марках?
q Как производится суждение о подобии? Помимо сравнения пар можно использовать так называемый фокальный объект, тогда подобие определяется по отношению к нему.
q Как производить агрегирование суждений, то есть обобщение ответов нескольких респондентов? Этот вопрос наиболее сложен. Все мнения различны, а усреднение может скрыть важные сегменты рынка. У двух опрашиваемых могут получиться очень схожие по виду карты, основывающиеся на совершенно разных критериях о подобии. Предложены алгоритмы агрегирования, которые основываются на предположении, что все респонденты используют одинаковые критерии, но с разными весами.
Отсутствие атрибутов при опросах играет положительную роль, так как иногда респондент не в состоянии объяснить, почему он считает данные элементы исследования похожими или различными. В данном случае это пытается сделать за него исследователь. Однако это очень трудный процесс. В некоторой степени он сродни искусству.
Главные проблемы – именование атрибутов и агрегирование суждений, полученных от разных респондентов.
Если количество объектов менее 8, то легко переупростить проблему. С другой стороны, при большом количестве объектов от опрашиваемого требуется большой объем работы. Он может сделать ее небрежно, тогда и результат будет сомнительным.
В атрибутных методах требуется рассматривать все потенциально важные атрибуты, но чаще сравнение происходит не по отдельным атрибутам, а по некоторой интегрированной оценке.
***
Итак, карты восприятия позволяют выявить основные атрибуты, воспринимаемые на рынке, предпочтительные комбинации атрибутов, выделить продукты, которые рассматриваются как аналоги, узнать жизнеспособные сегменты рынка и те характеристики товара, которые позволят ему занять новое место на рынке.
Похожие статьи